



Doménová adaptace překladače
V článku Nový překladač Lingea jsme představili nové verze našich překladačů založených na neuronových sítích. Mimo jiné jsme zde zmínili problematiku přípravy překladačů „na míru“.
Jak tedy vypadá příprava takového překladače v praxi a jaké výsledky můžeme očekávat?
Proces přizpůsobení obecného překladače se nazývá doménová adaptace. Obvykle postupujeme tak, že nejdříve natrénujeme překladový model na obecných datech pro daný jazykový pár. Mezi taková data patří například přeložené novinové články, manuály různých aplikací, články z Wikipedie, projevy z Evropského parlamentu, titulky k filmům a seriálům a mnohá další. Takto připravený základní překladač můžete vyzkoušet například na https://prekladac.lingea.cz/.
Poté je potřeba získat trénovací data z dané domény – doména může být poměrně obecná, například zdraví, cestovní ruch nebo webový prodej služeb, ale i specifičtější, například uživatelské příručky k pračkám. Ideální jsou paralelní data, tedy taková, kde jsou k dispozici zdrojové věty i překlad. V některých případech k efektivní adaptaci stačí i text, který je k dispozici pouze v cílovém jazyce. Vždy je ale potřeba velké množství těchto dat – minimálně desetitisíce, spíše však statisíce vět. Tato data můžeme přímo použít jednak pro trénování, jednak pro výběr dalších vhodných překladů z obecných korpusů na základě podobnosti textů.
Jakmile máme připravený trénovací korpus, můžeme konečně provést vlastní doménovou adaptaci, která spočívá v dotrénování obecného modelu s použitím vybraných doménových dat. Na malé části dat, která jsme ponechali stranou, můžeme pak sledovat kvalitu překladu a na základě toho provádět změny v procesu přípravy dat a trénování modelu, dokud nedosáhneme uspokojivého výsledku. Konečný výsledek, tedy rozdíl mezi adaptovaným a neadaptovaným modelem, můžete posoudit na následujících obrázcích.
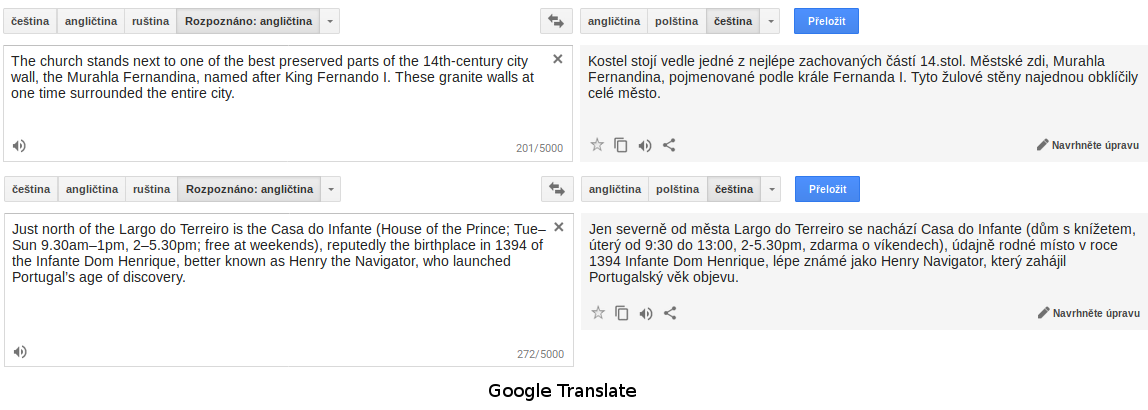 Na první obrazovce vidíte výsledky překladu pomocí služby Google Translate. Výsledný text je sice česky, ale není příliš srozumitelný, bez přečtení původního anglického textu uživatel někdy těžko chápe, o čem se v odstavcích píše.
Na první obrazovce vidíte výsledky překladu pomocí služby Google Translate. Výsledný text je sice česky, ale není příliš srozumitelný, bez přečtení původního anglického textu uživatel někdy těžko chápe, o čem se v odstavcích píše.

Na této obrazovce je výsledek obecného překladače Lingea. Text je o poznání čitelnější, ale stále to není úplně ono.

Zde vidíte výsledek překladu, který vznikl adaptací obecného překladače na texty z oblasti cestovního ruchu. Vidíte, že výsledný text je krásně čitelný a téměř bez chyb.
Je zřejmé, že takto vytvořený speciální překladač dokáže překladatelům ušetřit spoustu času a zkrátit proces lokalizace textů do češtiny. Současně ale musíme zdůraznit, že samotná příprava vyladěného překladače trvá několik dní či týdnů a vyplatí se proto až při překladu většího množství textu, řádově stovek či tisíců normostran.